
Superamento delle difficoltà legate all’analisi cellulare ad alto contenuto attraverso l’IA/apprendimento automatico
L’uso dell’intelligenza artificiale (IA) si sta diffondendo in molti aspetti della vita moderna, dai veicoli a guida autonoma agli assistenti personali ad attivazione vocale e anche nel campo della creazione artistica. Ma è l'applicazione nella scienza e nella salute che fa davvero risaltare i benefici dell'IA. Una di queste applicazioni si trova nell'analisi di immagine biologica o nell'analisi ad alto contenuto (HCA).
Con l’avanzare dell’HCA e l’accresciuta adozione come strumento quantitativo per la ricerca biomedica, lo spazio applicativo continua a crescere e non è più limitato a un elenco finito di test ben definiti eseguiti in modelli biologici standard. Per tenere conto di questa maggiore complessità, è stata posta una grande attenzione al miglioramento della flessibilità e delle prestazioni dei metodi di analisi attraverso l'IA o l'apprendimento macchina. In effetti, ci sono molti esempi in cui supera i metodi tradizionali per le applicazioni in molte discipline scientifiche.
Fino a poco tempo fa, l’uso di questi metodi di macchina più complessi è stato in gran parte riservato ai gruppi di ricerca che hanno un adeguato accesso a competenze specialistiche nella tecnologia dei dati e nello sviluppo di software personalizzati. Qui, forniamo una breve introduzione all'IA ed esploriamo come le soluzioni software di macchina learning chiavi in mano stanno consentendo ai ricercatori di sfruttare tutti i contenuti in un'immagine ed eseguire un'analisi più completa, rimuovendo al contempo il peso della complessità per l'utente.
Che cos'è l'IA o il macchina learning?
il macchina learning è una forma di IA (intelligence artificiale). Apprendimento profondo. Reti neuriche. Questi sono tutti termini leggermente diversi per l'IA, che il dizionario di Oxford definisce come:
“La teoria e lo sviluppo di sistemi informatici in grado di eseguire attività che richiedono normalmente l’intelligence umano, come la percezione visiva, il riconoscimento del linguaggio, il processo decisionale e la traduzione tra le lingue”.
Fondamentalmente, l'IA rappresenta qualsiasi informazione dimostrato dalle macchine che imita le funzioni cognitive che di solito assoceremmo alle menti umane come l'apprendimento, la risoluzione dei problemi e il ragionamento. Il macchina learning è una tecnica utilizzata dagli esperti per consentire ai computer di imparare rapidamente dai dati.
Superare le complessità di un flusso di lavoro HCA
In linea di massima, uno screening ad alto contenuto o un flusso di lavoro HCA, come il nostro ImageXpress Confocal HT.ai non è altro che la microscopia automatica seguita dall’analisi automatica delle immagini. Durante la fase di acquisizione, le immagini vengono acquisite da più campioni in piastre di microtitolazione. Ciò può comportare la raccolta di una grande quantità di dati di immagine se si sta tentando di comprendere, ad esempio, un farmaco efficace per salvare alcuni fenotipi malati.
La parte di analisi del flusso di lavoro può essere divisa in due parti: l'analisi delle immagini e l'analisi a valle. Durante l'analisi delle immagini, determinate caratteristiche e misurazioni vengono estratte dall'immagine e convertite in un formato in cui è possibile applicare l'analisi statistica. L’analisi a valle prevede la raccolta di tutti i dati ad alta dimensione e la loro distillazione in un formato che gli esperti possono interpretare e trarne le conclusioni in modo da poter procedere alla fase successiva del loro progetto di ricerca.
Il mondo di oggi dello screening ad alto contenuto è molto più completo quando si tratta di comprendere e descrivere un fenotipo. Invece di estrarre una singola funzione o di prendere un rapporto di alcune misurazioni diverse, i ricercatori stanno estraendo migliaia di funzioni per ogni cella all'interno di un'immagine. Ciò non richiede che sappiano qual è il target di un farmaco o che comprendono completamente la funzione di un gene. È semplicemente alla ricerca di differenze tra due diverse condizioni, facendo leva su tutti i contenuti di informazioni all'interno dell'immagine.
Con l'aumentare della complessità di alcuni test e l'estrazione di ulteriori informazioni da una singola cella, i dati diventano ancora più travolgenti. Quindi, come si dà un senso a tutte queste informazioni e le si distilla in qualcosa che è fruibile?
I metodi tradizionali di analisi delle immagini possono essere particolarmente complessi e dispendiosi in termini di tempo se eseguiti manualmente o addirittura semiautomaticamente. C'è sempre la possibilità di errore umano e di bias a causa della natura difficile ed estremamente dettagliata del compito. Considerando anche il carattere ripetitivo, prolungato e spesso laborioso del flusso di lavoro, esiste l’opportunità di applicare l’apprendimento automatico. L'IA rimuove qualsiasi variazione da persona a persona, errore umano e bias, aumentando così la qualità e la sicurezza dei dati, nonché ottimizzando il flusso di lavoro e l'efficienza.
Superare il bias umano
Uno dei vantaggi chiave del macchina learning nell’HCA che richiede una nota speciale è la capacità di superare i condizionamenti dell’uomo. Quando si studiano set di dati di grandi dimensioni, gli individui sono esposti a un fenomeno ben descritto chiamato “cecità sorvegliante”. È qui che le osservazioni impreviste passano inosservate quando si eseguono altre attività che richiedono attenzione.
Per esempio, avendo precedentemente studiato un particolare fenotipo cellulare e una risposta in dettaglio, si potrebbe essere involontariamente alla ricerca di quegli stessi segni quando si presentava con un grande set di dati complessi contenente molte variabili e misure. In questo modo, si potrebbe quindi trascurare un'altra caratteristica sottile o imprevista che ha anche una pertinenza biologica.
Il macchina learning aiuta a superare questa vulnerabilità, eseguendo una classificazione completamente imparziale, con il potenziale di produrre risultati imprevisti e di valore.
Applicazione dell’apprendimento macchina alla segmentazione degli oggetti
I dati quantitativi affidabili sono vitali per ogni fase a valle del flusso di lavoro HCA, con la prima segmentazione. La Segmentazione è il processo di estrazione degli oggetti di interesse (ad es., gli organoli) dalle immagini e quindi di quantificarne le caratteristiche. Fondamentalmente, è il primo passo per convertire i pixel di immagine in dati numerici.
La Segmentazione può essere impegnativa, specialmente quando si lavora con metodi di elaborazione del segnale tradizionali, progettati per mettere a fuoco un oggetto. Nelle immagini microscopiche di cellule o tessuti, gli oggetti sono in genere affollati o raggruppati insieme. Inoltre, hanno dimensioni e forme diverse. Spesso c'è il problema di scarso segnale-rumore, basso contrasto e scarsa risoluzione delle immagini. Per non parlare del fatto che ci può essere un'alta variabilità fenotipica a causa di perturbazioni chimiche o eterogeneità naturale nel tipo di cellula stesso.
Per affrontare le difficoltà della segmentazione, è possibile applicare gli Algoritmi di apprendimento profondo alla parte di analisi delle immagini del flusso di lavoro HCA. Ad esempio, il software di analisi delle immagini IN Cartaý include un modulo basato sul deep learning chiamato SINAP progettato per funzionare con una vasta gamma di dati.
Poiché SINAP utilizza il deep learning, può tenere conto di grandi quantità di variabilità nell'aspetto del campione che deriva dai trattamenti di prova in fase di indagine. Assicurando che ogni trattamento sia segmentato con un livello di precisione equivalente, le informazioni estratte in questa fase possono essere utilizzate in modo affidabile per confrontare i trattamenti nelle fasi successive dell’analisi.
Esempi di modulo IN Carta SINAP in uso:
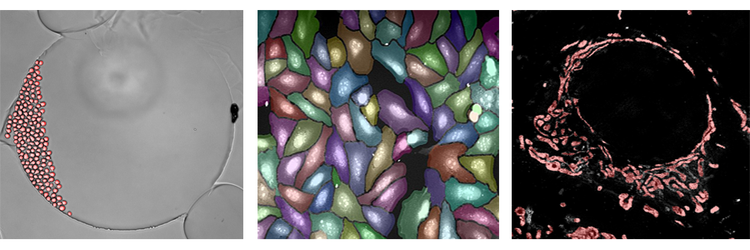
Di seguito sono riportati alcuni esempi dell’algoritmo di deep learning SINAP applicato a tre set di dati completamente diversi. L'analisi del campo chiaro è raffigurata nella figura all'estrema sinistra. L'analisi è davvero la segmentazione a cella singola nel tempo, osservando le cellule viventi dividersi e muoversi. La figura centrale mostra la segmentazione di un test di pittura cellulare. Anche se le celle sono affollate, SINAP è in grado di segmentare gli oggetti con alta precisione. Infine, la figura all'estrema destra proviene da un'immagine superrisoluzione di mitocondri. Ancora una volta, anche se questo contenuto è completamente diverso, lo stesso flusso di lavoro e lo stesso algoritmo possono essere utilizzati per esaminare i singoli mitocondri nelle fonti di dati e nell’immagine. In tutti e tre i casi, è possibile completare con maggiore precisione e affidabilità la segmentazione con facilità utilizzando l'algoritmo di apprendimento profondo SINAP.
Applicazione dell'apprendimento macchina alla classificazione degli oggetti
Poiché si sta tentando di sfruttare il maggior numero di contenuti possibile in un flusso di lavoro HCA, è importante assicurarsi che il contenuto abbia un certo grado di qualità prima di raggiungere la fase di analisi a valle. È qui che entra in gioco la classificazione degli oggetti. La classificazione degli oggetti è il processo di divisione dei set di dati in sottopopolazioni in base al fenotipo (ad es. morfologia cellulare, localizzazione sub-cellulare, livello di espressione di marker specifici).
È possibile utilizzare uno strumento di classificazione per selezionare manualmente le funzioni rilevanti e assegnare lezioni, ma ciò è applicabile solo alle modifiche fenotipie semplici in base ad alcune misure. Ad esempio, si potrebbe determinare una fase del ciclo cellulare in base all'intensità del colore nucleare o classificando le cellule viventi o morte in un test di vitalità. Per tutto ciò che riguarda un set più esteso di funzionalità, l'uso dell'IA per la classificazione degli oggetti diventa un'opzione migliore.
Con il macchina learning, l'utente umano non deve più selezionare manualmente misure o soglia. Invece, questa attività è assegnata al computer. L'utente umano fornisce gli esempi di computer di differenti categorie di celle. Il computer capisce come differenziare queste lezioni. In pratica, il computer sta apprendendo le caratteristiche più appropriate e ha il vantaggio extra di poter imparare la giusta combinazione di caratteristiche.
Il software IN Carta include anche un modulo di classificazione a livello di oggetto formabile chiamato Fenoglifi. Il modulo Fenoglifi utilizza le informazioni estratte da SINAP per raggruppare gli oggetti con un aspetto visivo simile. Questa procedura permette di valutare se un trattamento genera un fenotipo favorevole e anche di dedurre il meccanismo di base coinvolto. Grazie all’uso dell’apprendimento automatico, è possibile analizzare simultaneamente tutte le caratteristiche visive per ottimizzare il complesso set di regole necessarie per assegnare gli oggetti al gruppo corretto. Questo approccio estremamente multivariato e guidato dai dati è molto più in grado di risolvere sottili differenze fenotipiche ed è più robusto rispetto all’assegnazione di oggetti al gruppo errato.
Le quattro fasi della formazione del modulo IN Carta Phenoglyphs:
- Gruppo: Il modulo seleziona e utilizza automaticamente le misure calcolate durante la segmentazione per creare raggruppamenti naturali nei dati, chiamati gruppi, senza bias umano.
- Etichetta: L'utente seleziona ed etichetta tutte le lezioni valide (almeno due) per la classificazione e la formazione.
- Classifica: Il modulo classifica l’elenco delle misure utilizzate per partizionare gli oggetti in classe e offre l’opportunità di deselezionare le misure con informazioni ridondanti o poco impatto.
- Addestramento: Il modulo rifinisce il modello di classificazione in base all'input dell'utente, compresa la rimozione di oggetti o la riassegnazione a lezioni più appropriate.
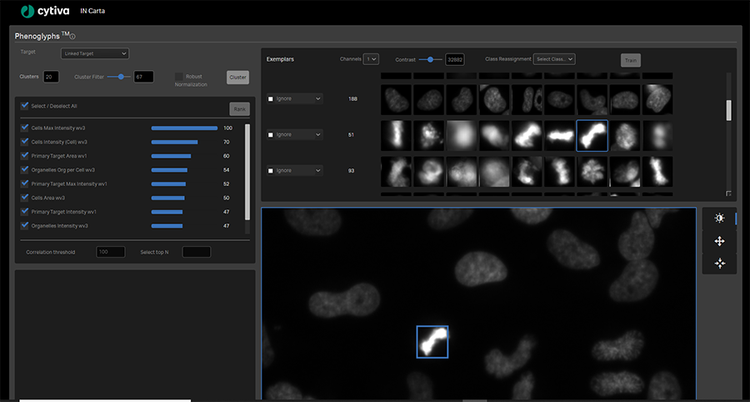
Formazione del modulo di classificazione dell’apprendimento macchina Phenoglyphs
L’utente dovrà semplicemente esaminare un piccolo numero di esempi per ogni classe e fornire il proprio input prima che il modulo Phenoglyphs applichi il modello all’intero set di dati. Questo approccio riduce al minimo la necessità di input da parte dell'utente nella prima fase dell'assegnazione della classe, facendo risparmiare tempo considerevolmente.
Rimuovere le congetture
Unico per il software IN Carta è il passo iniziale non controllato che è integrato sia nei moduli SINAP che nei moduli fenoglifis. Il passo non monitorato genera un risultato iniziale che viene ottimizzato in modo iterativo semplicemente facendo confermare o correggere la decisione dell'algoritmo all'utente. Questo rimuove l’onere di determinare un punto di partenza fattibile per l’analisi ed elimina la necessità di modificare i parametri in una noiosa prova e in un modo di errore. Abbinando SINAP e fenoli, gli utenti sperimentano un flusso di lavoro end-to-end che non richiede alcuna esperienza precedente nell’analisi di immagini o statistiche ed è semplificato per ridurre i tempi di realizzazione dei risultati.
Scopri di più sull'ottimizzazione del flusso di lavoro HCA con il machine learning. Visualizza la nostra pagina del software IN Carta.